Have insights to contribute to our blog? Share them with a click.

1. The Hidden Foundation Behind Successful AIOps
You don't have a monitoring problem. You have a data problem.
Most banks across Singapore, Malaysia, and the Philippines are not under-monitored. They are running multiple enterprise monitoring platforms, vendor-specific tools, and a NOC dashboard on top of that.
The alerts are firing. The dashboards are live. The on-call engineer's phone is going off at 3am.
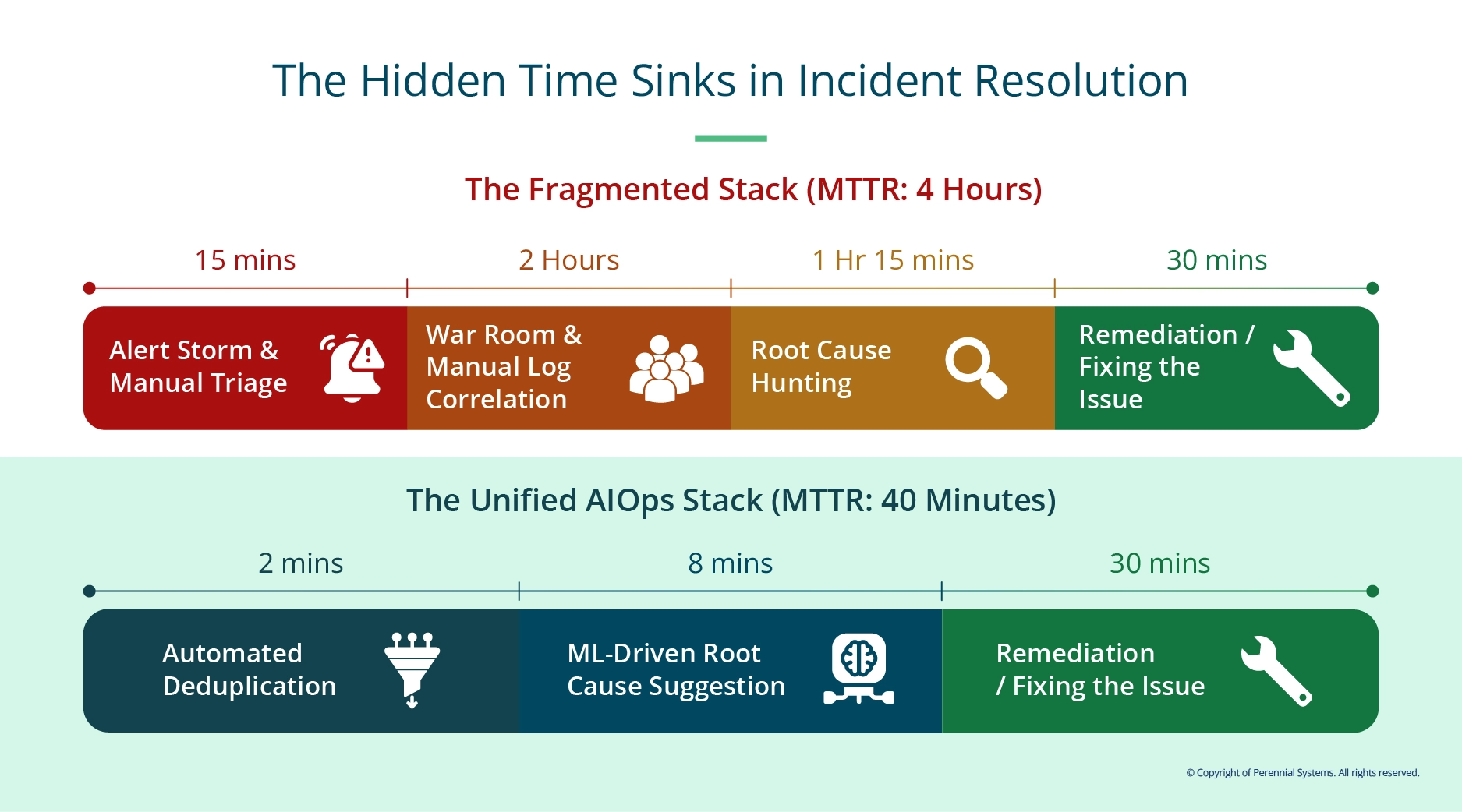
And the incident still took four hours to resolve, because no one could read all those signals together fast enough to matter.
That is not a monitoring gap. That is a fragmentation problem dressed up as one.
1.1 Why More Data Doesn't Always Create Better Visibility
Every monitoring tool your team adds solves a specific visibility problem and creates a new integration problem. Logs live in one place.
Traces in another. Infrastructure metrics somewhere else. Each tool applies its own severity labels, its own tagging conventions, its own definition of what constitutes an alert worth firing.
When an incident hits, engineers are not investigating. They are translating, switching between consoles, manually correlating timestamps, rebuilding a picture of what happened from five different incomplete sources. The tools are all present. The signal is not.
More data without a shared structure does not create better visibility. It creates more places to look when something breaks.
1.2 What High-Quality Operational Signals Actually Look Like
A unified signal layer does not mean fewer tools. It means one ingestion pipeline that every tool feeds into normalized, tagged consistently, and correlated by design before it reaches any engineer or any model.
In practice this means a shared tagging schema across service, environment, and release version. A service dependency map that is query able, not reconstructed under pressure.
And every deployment event is timestamped and written into the same pipeline as your runtime telemetry, so when a release causes a regression, the signal-to-cause path is already drawn.
That last point matters more than most teams realize. Most incidents in banking environments are change-induced. If your change events are not in your observability pipeline, your correlation engine is working without the single most predictive signal available.
1.3 The Missing Data Layer in Most AIOps Strategies
This is where most AIOps strategies stall, not at the intelligence layer, but at the data layer beneath it.
Banks invest in an AIOps platform, point it at existing monitoring data, and find that anomaly detection fires constantly and incorrectly. The conclusion drawn is that the model is underperforming.
The actual problem is that the input data has no consistent baseline to learn from. Fragmented sources, inconsistent tagging, and missing change events mean the model is pattern-matching on noise.
The missing layer is not another tool. It is the normalization, correlation, and dependency infrastructure that makes the data coherent enough for any intelligence layer to work on.
Fix the data layer first. Everything above it works correctly once the foundation is right.
1.4 Where AI and ML Deliver Real Operational Value
When the ingestion pipeline is unified and the signal layer is clean, the AI & ML solution delivers what the vendor promised in the demo.
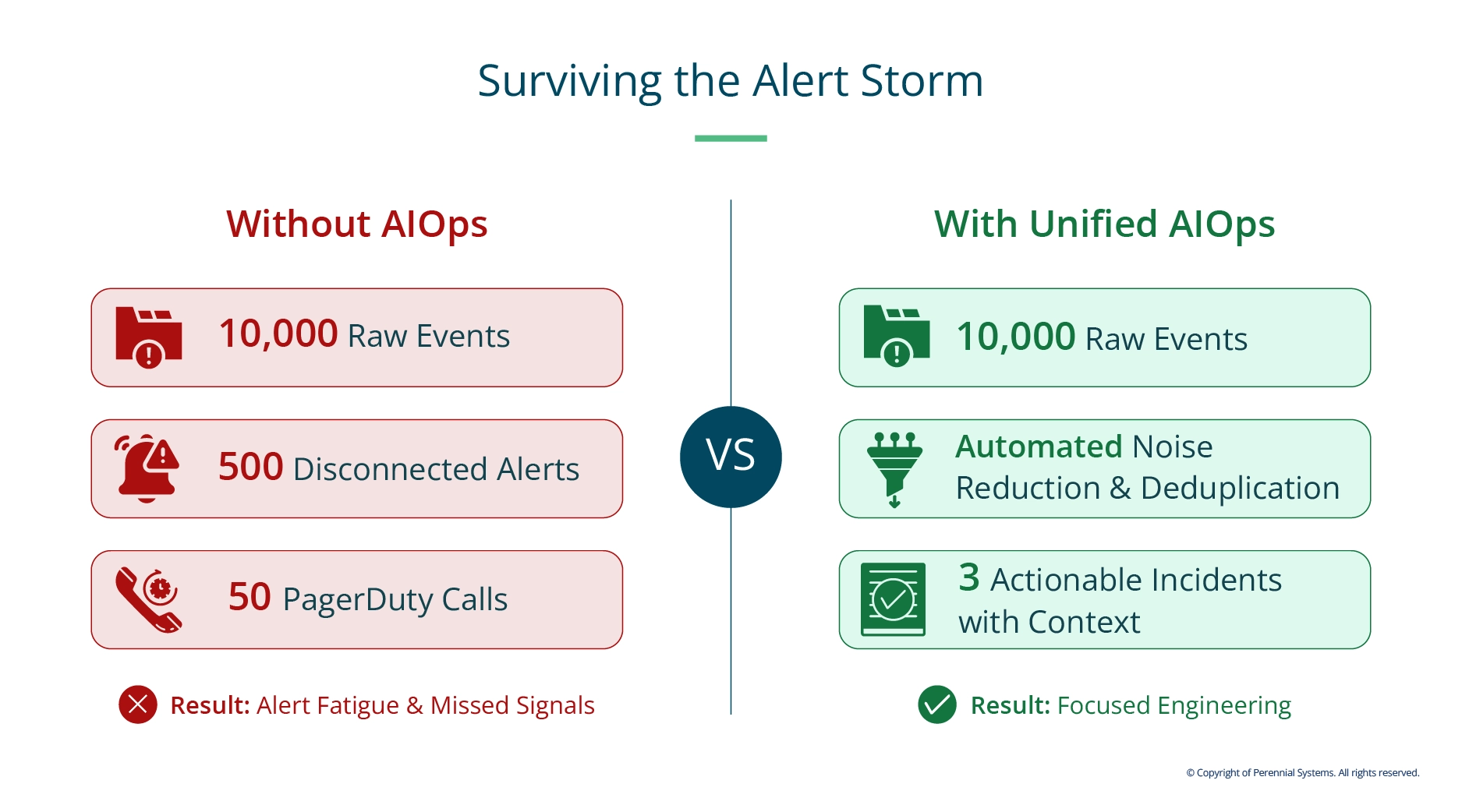
Deduplication becomes automatic, alerts that were firing as twenty separate events collapse into one grouped incident with a blast radius map attached. Correlation becomes a query, not an investigation.
Anomaly detection runs against real baselines rather than fragmented, inconsistent history. Root cause suggestion surfaces probable causes in seconds rather than after a two-hour bridge call.
The maturity jump from reactive operations to intelligence-driven operations does not come from a better model. It comes from better data feeding the model you already have.
1.5 Take the AIOps Scorecard to find your signal gap
If your team is still triaging across multiple monitoring tools with no shared signal layer, the bottleneck is in the data foundation, not the AI on top of it.
The BFSI AIOps Scorecard Assessment benchmarks your current stack across ten operational dimensions, including signal normalization, dependency mapping, and ML readiness. It identifies specifically where your data layer is breaking down and what the remediation path looks like.
Take the Scorecard at or request a 30-minute observability architecture review with our engineering team.
Acknowledgments
This article was shaped through engineering insight, strategic thinking, and real-world AIOps implementation experience.
Author
Nilesh Bafna
Nilesh brings deep technical expertise in AI infrastructure and enterprise observability, grounding this piece in the architectural realities that BFSI engineering teams face every day.
Contributor
Sahil Mahalley
Sahil contributed to the article by helping frame the core narrative, ensuring the key ideas around signal fragmentation and data-layer remediation were structured clearly and compellingly.
Design & Visuals
Shriram Pathak
Shriram translated operational complexity into intuitive visuals that simplify architecture, telemetry, and correlation workflows.
Tech Partners
Ruchil Shah & Varsha Shinde
Ruchil and Varsha brought technical depth and implementation perspective, grounding the guide in scalable engineering and operational practices.
Web & Digital Experience
Javed Tamboli
Javed crafted the digital experience, ensuring the guide feels seamless, polished, and easy to navigate across platforms.


Nilesh Bafna
About the Author
I'm Nilesh, CTO at Perennial Systems. Over 20 years across UAE, India, and the Maldives have taught me one thing: most technology transformations don't fail because of bad strategy. They fail because the fundamentals weren't right to begin with.
I build large-scale solutions on Cloud, DevOps, and AI platforms. Right now, a big part of my focus is Agentic AI, getting automation out of the boardroom and into production, where it actually does something useful.
I write for technology leaders who are in the middle of making hard decisions and want a straight perspective from someone who has been in the same room.
Off the clock? Still thinking about infrastructure. Some habits don't switch off.
Have insights to contribute to our blog? Share them with a click.
0 comments